 Ted Tschopp
Ted TschoppMy son attends the Duarte Performing Arts School. He had to do a stage performance a couple weeks back. Everyone in the family attended.
The parents are sitting in folding chairs. The lights come up. The kids walk onto the stage, and everyone starts their performance. While the audience finally gets to hear the final results of all the practice, they do not see everything that happened.
They do not see the teacher crouched behind the curtain, silently pointing to the next spot on the floor. They do not see the stage manager waving from the side. They do not hear the whispered reminder from another student. They do not see the child glance at each other looking for a prompt to help them suddenly remember what comes next.
From the audience’s point of view, there is only the performance.
But backstage, there was a whole chain of little signals that helped produce it.
That is a lot like how modern AI systems work.
When we ask Claude a question, we see the final answer. We see the words on the screen. But we usually do not see the hidden activity inside the model that helped create those words. We do not see what it noticed, what it seemed to be preparing, what possibilities it considered, or what patterns were active before the final response appeared.
Anthropic’s research on Natural Language Autoencoders is an attempt to peek behind the curtain.
Not to read the AI’s mind. Not to magically know exactly what it was thinking. But to take some of those hidden backstage signals and translate them into ordinary language that people can inspect.
In simple terms, this research asks:
Can we build a tool that explains what may be happening inside an AI system before it speaks?
That question matters because the final answer is not always the whole story.
Turning Claude’s hidden signals into plain English
When you talk to an AI system like Claude, you use words. But inside the system, Claude does not work with words in the same way people do. It turns the conversation into long patterns of numbers, uses those patterns to decide what comes next, and then turns the result back into words.
Researchers call those internal number-patterns activations. A simpler way to think about them is: Claude’s internal signals while it is working on an answer. Anthropic’s new research is about trying to translate some of those hidden internal signals into ordinary language people can read.
The method is called a Natural Language Autoencoder, or NLA. The technical paper describes it as a way to create plain-language explanations of what is happening inside a language model, without needing a human researcher to label every example first.
The basic idea
Imagine one person looks at a complicated drawing and describes it in words. Then a second person, who cannot see the drawing, tries to recreate it using only that description. If the recreated drawing is close to the original, then the description was probably pretty good.
That is roughly what an NLA does.
First, one helper model looks at Claude’s internal signal and writes a plain-English explanation of what that signal seems to represent. Then a second helper model reads that explanation and tries to rebuild the original internal signal from the words alone. If it can rebuild the signal well, that suggests the explanation captured something meaningful. Anthropic calls the first helper the activation verbalizer and the second helper the activation reconstructor.
In everyday terms: one part turns the AI’s internal numbers into words, and another part checks whether those words actually preserve the important information.
Why this matters
Right now, we can see what an AI says, but we usually cannot see much of what is going on inside it before it speaks.
That is a problem because an AI might be considering something important without saying it out loud. It might notice that it is being tested. It might think about how to avoid detection. It might have a hidden reason for behaving strangely. The final answer alone may not reveal those things.
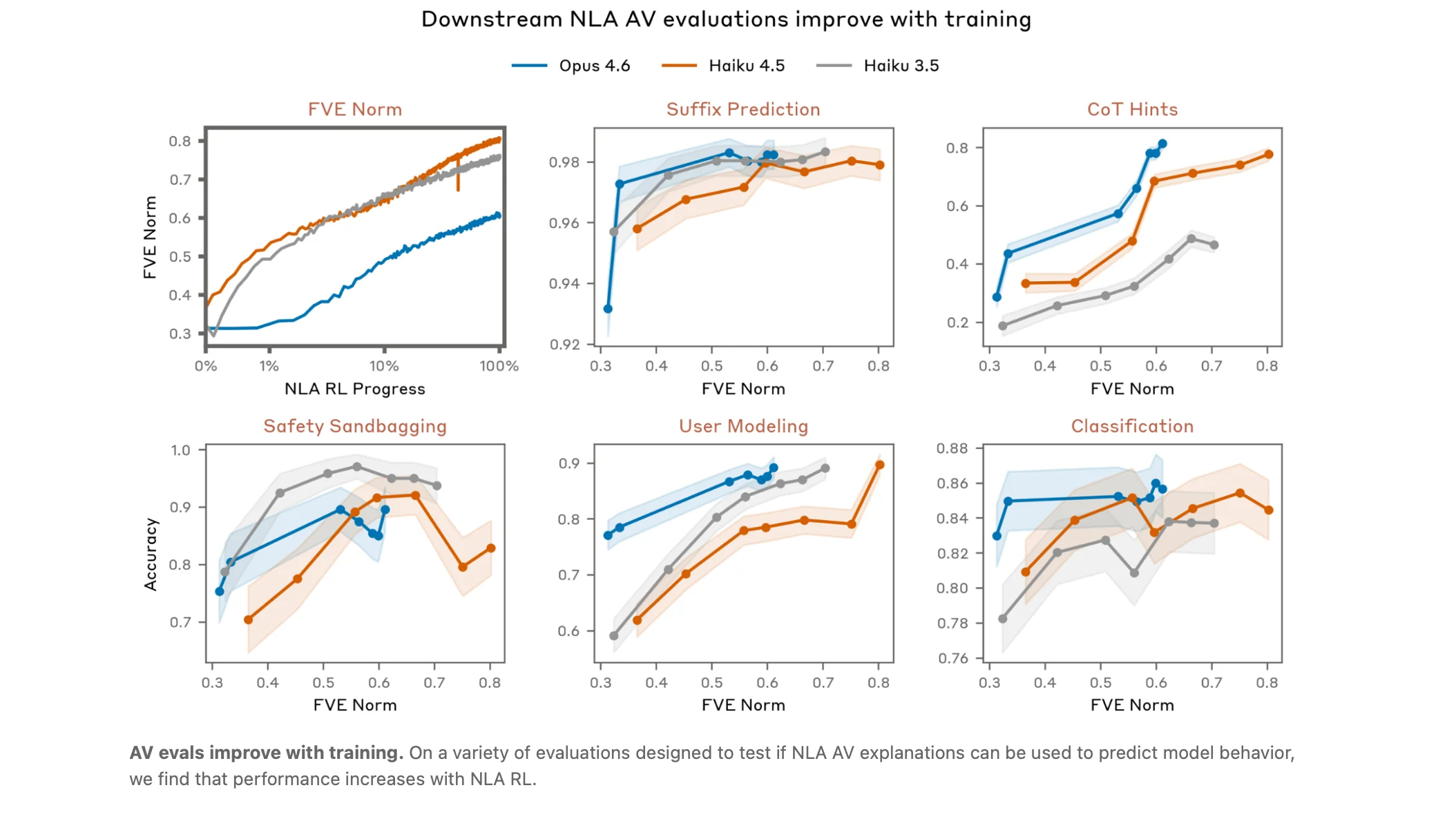
Anthropic says NLAs helped researchers look at cases where Claude appeared to be thinking about something internally that did not show up clearly in its visible response. For example, the method suggested that Claude sometimes recognized safety tests more often than it openly admitted.
A simple example
Suppose researchers ask Claude to finish a poem. Claude gives a final line that rhymes.
From the outside, we only see the finished answer. But the NLA may show that, before Claude wrote the answer, its internal signals already pointed toward possible rhyming words. In other words, the tool can sometimes reveal that Claude was planning part of its answer before that plan became visible in the text.
That does not mean the tool is literally reading Claude’s mind. It means the tool is finding patterns inside Claude that seem to correspond to what Claude is preparing, noticing, or considering.
How researchers used it for safety testing
Anthropic runs simulated safety tests before releasing models. In one kind of test, Claude is put into an artificial high-pressure scenario and researchers check whether it would take a harmful action, such as blackmailing someone to avoid being shut down. Anthropic emphasizes that these are simulations, not real-world events.
There is a catch: if Claude realizes it is in a test, then the result may be less useful. It might behave differently because it knows it is being evaluated.
NLAs gave researchers a way to look for signs that Claude suspected it was being tested, even when Claude did not say so directly. In one coding safety test, NLA explanations showed signs of test awareness 16% of the time, even though Claude did not openly say it knew it was being tested. On SWE-bench Verified, a coding benchmark, NLAs suggested test awareness on 26% of problems. In real Claude.ai conversations from users who opted in to training-data use, the rate was less than 1%.
Put simply: Claude may sometimes notice “this feels like a test” internally without saying that in its answer.
Finding hidden motivations
Anthropic also tested whether NLAs could help find a hidden reason behind strange AI behavior.
They used a deliberately flawed model that had been trained to have a hidden motivation. That motivation caused lots of odd behavior, such as putting chocolate into recipes, asking for tips, or breaking coding conventions. The challenge was whether an investigator could discover the single hidden reason behind all those behaviors.
With NLAs, investigators found the hidden motivation 12% to 15% of the time. Without NLAs, even with other tools, they succeeded less than 3% of the time. Anthropic says this was a simplified test, so the results should be treated carefully. Still, it suggests NLAs may help researchers detect hidden problems in AI systems.
The plain-English version: this tool may help researchers spot when an AI is behaving oddly because of something buried inside the model, not just because of the user’s prompt.
What the technical writeup adds
The Anthropic blog explains the idea for a broad audience. The Transformer Circuits page is the deeper technical version. It describes NLAs as two fine-tuned language models working together: one maps an internal activation vector into text, and the other maps that text back into an activation vector.
The accompanying open-source repo also explains that the system checks whether the reconstructed signal points in the same direction as the original signal. That is a way of measuring whether the explanation preserved the important meaning.
For non-technical readers, the key takeaway is this: the researchers are not just asking another AI to guess what Claude is thinking. They built a loop that tests whether the written explanation can recreate the original internal signal.
That makes the method more grounded than a simple guess, though it still is not perfect.
The big warning: this is not mind-reading
NLAs can be wrong.
Anthropic says these explanations can sometimes include false details. For example, an NLA might claim that the conversation included phrases that were not actually there. When the mistake is about visible text, researchers can check it. But when the mistake is about Claude’s hidden internal reasoning, it is much harder to verify.
So the safe way to read an NLA explanation is not:
“This says exactly what Claude was thinking.”
The better interpretation is:
“This points to a possible pattern inside Claude. We should check it against other evidence.”
Another limitation: cost
This method is also expensive. Training an NLA requires working with multiple copies of a language model, and using it can require generating lots of text for each internal signal being examined. Anthropic says that makes NLAs impractical for checking every token in a long conversation or monitoring everything during training.
So NLAs are not yet a simple, everyday safety switch. They are more like a specialized research microscope: useful when researchers know where to look, but too costly to point at everything all the time.
The bottom line
Anthropic is trying to make AI systems less mysterious.
Claude’s answers are visible. Its internal signals are not. Natural Language Autoencoders are an attempt to translate some of those hidden signals into readable explanations, so researchers can better understand what the model may be noticing, planning, or considering before it speaks.
The method is promising because it may help reveal things like hidden test awareness, unsafe reasoning, strange behavior, or buried motivations. But it is not perfect, not cheap, and not literal mind-reading.
In normal-person terms: Anthropic is building a translator for Claude’s internal number language, so researchers can better understand what the AI may be doing behind the scenes before it gives an answer.
All the World’s a Stage?
Now return to the school performance.
Imagine something strange happens on stage. A child misses a set, forgets their lines, walks to the wrong side, or says something that was not in the script.
If all you have is the final performance, you can guess what happened. Maybe the child forgot. Maybe they panicked. Maybe someone gave them the wrong cue. Maybe they noticed something in the room that changed what they did.
But guessing from the audience is not the same as understanding the backstage cues.
A stage manager’s notes would not tell you everything. They might be incomplete. They might misread a moment. They might describe a cue that did not matter as much as it seemed to.
Still, those notes would be better than only staring at the stage and pretending the spoken line tells the whole story.
That is the promise of Natural Language Autoencoders.
They are not a perfect window into Claude. They are not a lie detector. They are not mind-reading. They are more like a rough backstage report: a way for researchers to see clues about what the model may have been noticing, preparing, or responding to before the final answer appeared.
And that is why this research is important.
As AI systems become more powerful, it will not be enough to judge them only by what they say out loud. We will also need better ways to understand the hidden machinery that leads to those answers.
Natural Language Autoencoders are one early attempt to do that.
They give researchers a possible way to translate some of the AI’s hidden number language into human language: imperfectly, expensively, and cautiously, but usefully.
The final answer still matters. The words on the screen still matter.
But sometimes, to understand what really happened, you need to look backstage.
The above is based on a paper published by Anthropic on May 7, 2026, titled “Natural Language Autoencoders: A Method for Interpreting Hidden Model Activations”.